Métricas De Latência No CEPH
![]()
Neste post compartilharei um dashboard em grafana com metricas avançadas de latency/journal/queue/iops/throughput que te ajudaram a ajustar melhor as configurações do seu cluster, visto que pesquisando na internet não achei nenhum dash de ceph latência com telegraf, mas não era à toa, pois só na versão Lumiuous foi corrigido “admin socket permission” então resolvi criar do zero e compartilhar com a comunidade, explicando os principais pontos para utilizar tanto no jewel quanto no luminous.
Não irei abordar instalação do influxdb, grafana e telegraf pois tem muita coisa na internet, apenas os pontos principais para o dashboard funcionar.
Com o comando abaixo é possível verificar media latência do commit e apply do Ceph
# ceph osd perf
commit_latency(ms) apply_latency(ms)
............... ......................
Comentarei os 4 mais importantes:
A gravação do objeto em um cluster com replica de 3 gastará 6 IOs, para se concluido por conta da gravação journal(O_DIRECT) e do buffered_io para o disco efetivamente nas OSDs. Na maioria das vezes veremos mais IOs de write por conta das suboperações do ceph de replicação, diferente do read que só faz leitura na OSD primaria.
- ops - Operações nas OSDs.
- Journal_latency - Tempo que leva para gravar no journal, ou seja, tempo de ack do write para o cliente.(O_DIRECT e O_DSYNC)
- apply_latency - Tempo de latência até a transação termina, ou seja, o tempo de gravação + journal.
- commit_latency - Tempo que leva para realizar o syncfs() após a expiração do filestore_max_sync_interval, no caso a descida do journal para o disco.
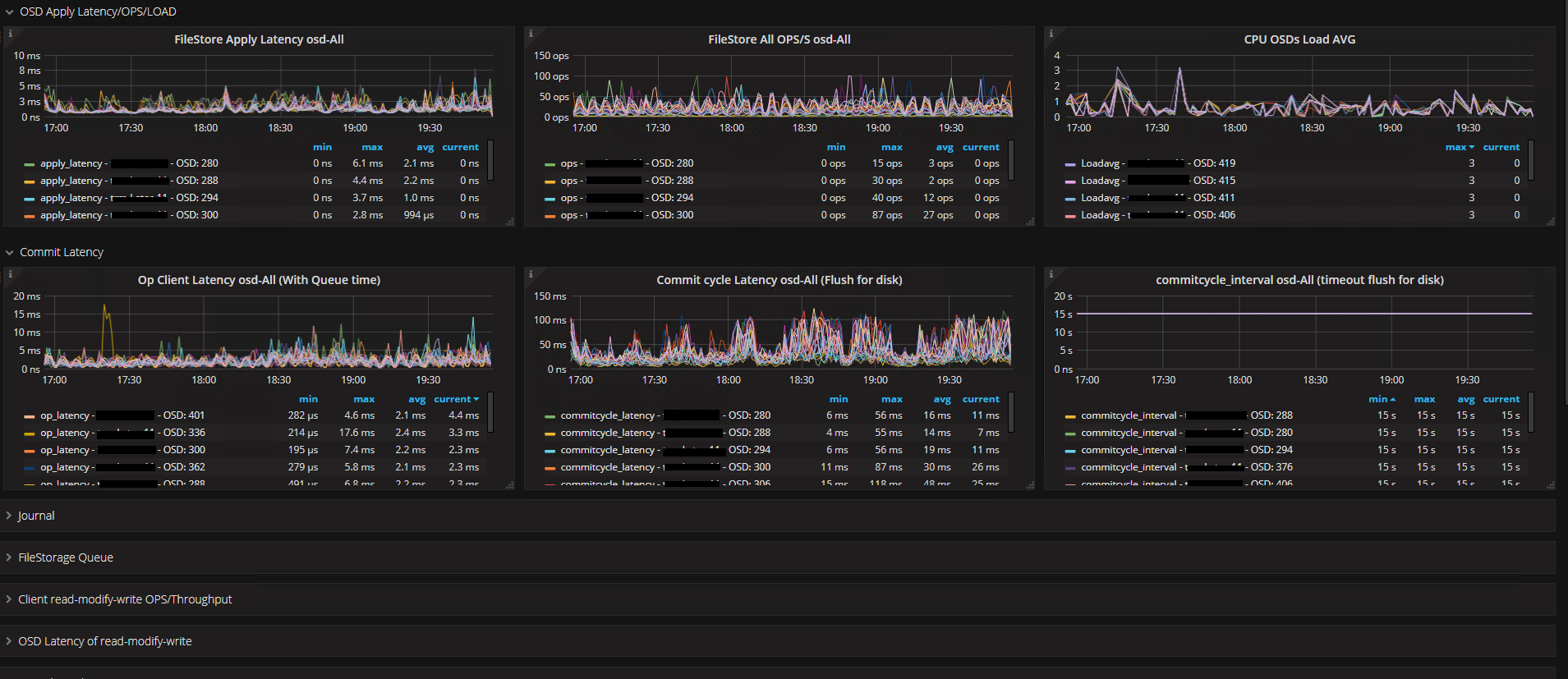
As métricas acima são as que nos dão uma media de como anda a latência do nosso cluster, o dashboard abaixo irá apresentar no grafana essas informações entre outras.
Por padrão algumas métricas de subsystem do cluster Ceph já vem ativo, outras teremos que ativar no ceph.conf ou via OSDs com inject. Verifique se seu cluster está com os perfs true.
# ceph --admin-daemon /var/run/ceph/ceph-osd.26.asok config show | grep perf
"debug_perfcounter": "0\/0",
"perf": "true",
"mutex_perf_counter": "true",
"throttler_perf_counter": "true",
Crie o arquivo abaixo e não esqueça de adicionar as tags para facilitar a seleção no grafana entre SATA e SSD ou escolha uma tag de sua preferência.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
Será nescessario adicionar o usuario telegraf no grupo ceph para que ele possa ler os sockets do /var/run/ceph
# addgroup telegraf ceph
ATENÇÃO: Aqui está o pulo do gato, nas versões anteriores ao Ceph 12.0.3 Luminous, terá que executar o seguinte comando abaixo
# chmod g+w /var/run/ceph/*
Esse comando contorna o problema “admin socket permission” que foi corrigido nas versões acima da 12.0.3
common: common/admin_socket: add config for admin socket permission bits (pr#11684, runsisi) https://github.com/ceph/ceph/pull/11684
Se a OSD for reiniciada a permissão se perder, se estiver abaixo da 12.0.3, recomendo adicionar a permissão no systemd após o startup da OSD. Se já estiver na versão superior basta adicionar no ceph.conf a config abaixo
admin_socket_mode 0775
Reiniciei o telegraf
systemctl restart telegraf
Verifique se não está ocorrendo nenhum error de socket no syslog
telegraf[986875]: 2018-09-18T21:49:03Z E! error reading from socket '/var/run/ceph/ceph-osd.51.asok': error running ceph dump: exit status 22
Teste se o telegraf está coletando as metricas do seu servidor de OSD com a permissão do telegraf
# sudo -u telegraf telegraf --debug -test -config /etc/telegraf/telegraf.conf -config-directory /etc/telegraf/telegraf.d -input-filter ceph
# sudo -u telegraf ceph --admin-daemon /var/run/ceph/ceph-osd.14.asok perf dump
Se tudo estiver ok, basta importa o dashboard para seu grafana e ser feliz! :)
Dashboard Telegraf Ceph - Latency: https://grafana.com/dashboards/7995
Plugin Utilizado: https://github.com/influxdata/telegraf/tree/master/plugins/inputs/ceph
No próximos post irei apresentar:
- Melhores práticas com Ceph - Desde o Hardware, S.O e configurações do ceph.conf para você obter melhor performance do seu cluster.
Referências de métricas: